-
How to automate Cisco Anyconnect VPN with WSL2
Sometimes your job will force you to use antequated technology like a VPN client to access resources (ever heard of SSO??).. When that breaks things, it can be a pain. In my case, whenever I connect to Cisco Anyconnect VPN, I get booted off all my WSL2 SSH sessions. As I spend all day in a WSL2 Ubuntu terminal on my Windows 10 deskop machine, it gets a bit tedious to reconnect things whenever I am forced to use the VPN.
In my scenario, I connect to the VPN (which in my case is a split tunnel, which interferes with the
vEthernet (WSL)Hyper-V network adaptor that WSL2 uses. My sessions hang, I can’t resolve DNS etc. Disaster. To fix this issue, I can run the following 2 lines in an Administrator privileged Powershell window:Get-NetAdapter | Where-Object {$_.InterfaceDescription -Match "Cisco AnyConnect"} | Set-NetIPInterface -InterfaceMetric 4000 Get-NetIPInterface -InterfaceAlias "vEthernet (WSL)" | Set-NetIPInterface -InterfaceMetric 1This fairly self explanitory script bumps up the preference of the Cisco AnyConnect interface and drops the WSL down a peg or 3999. Note this is a metric, not a cost.
OK that’s fine, but doing that every time you connect to the VPN is annoying. To automate this, we can use Task Scheduler in Windows.
Before we start, we need to enable the running of scripts on our local machine. To do this, follow steps here. For reference, I only want my local machine to be able to run scripts created on this machine, so I ran:
Get-ExecutionPolicy -List Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUserStep 1: We open up Task Scheduler and create a new task. I found it important to run whether user is logged in or not, run with highest privileges and tell it to run as my user (who is local admin).
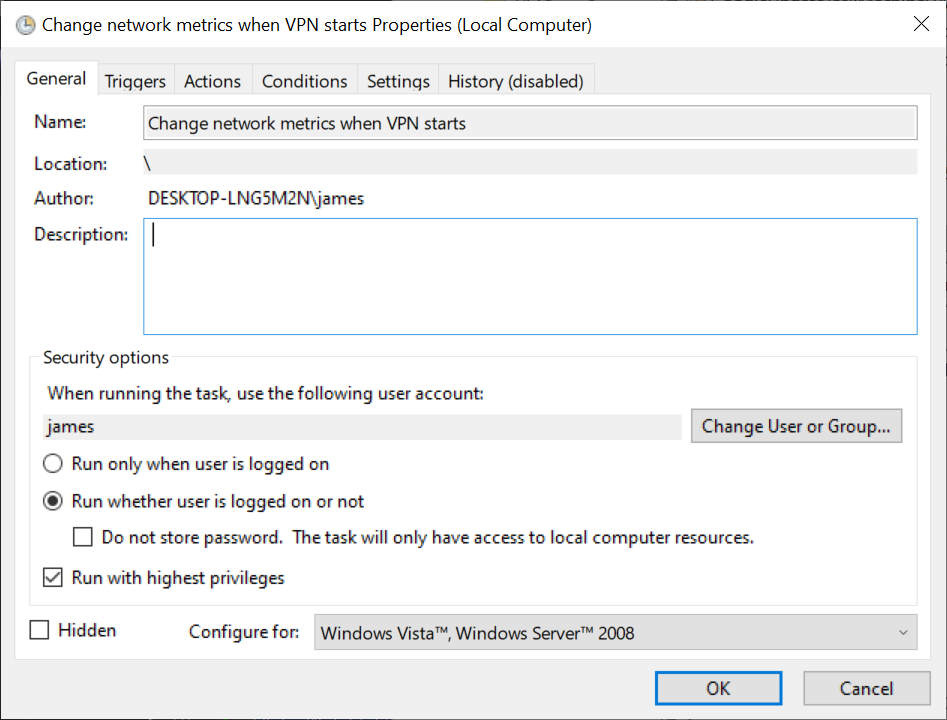
Step 2: We want to create a trigger for this event. Click New.. and get triggered
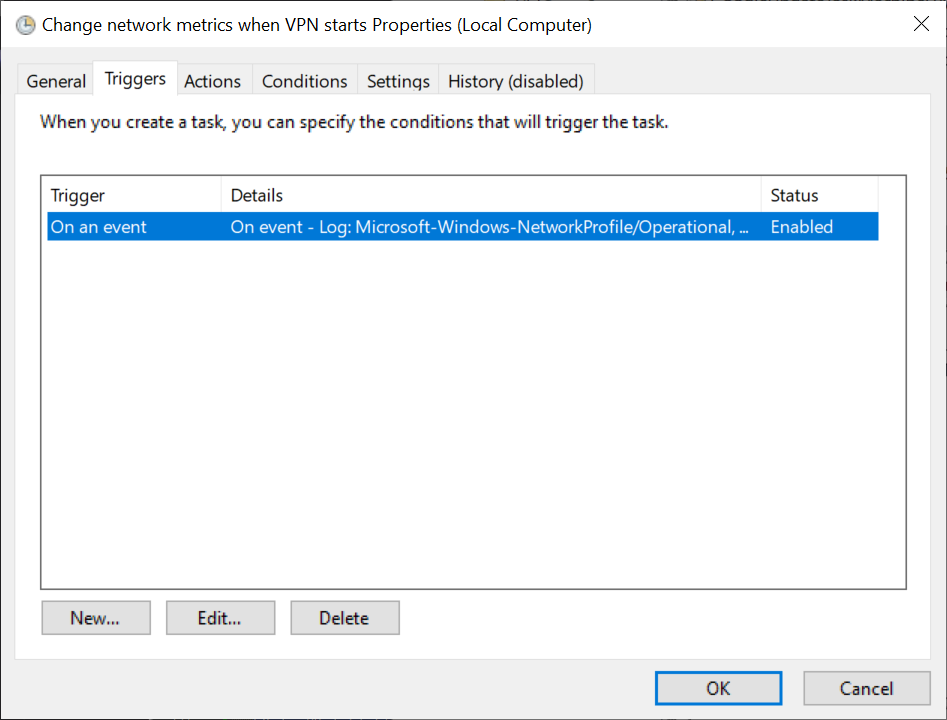
Step 3: Trigger the task
On an eventand useMicrosoft-Windows-NetworkProfile/Operationallog, withNetworkProfileas source, andEvent IDas 10000. This is when an interface goes up or down.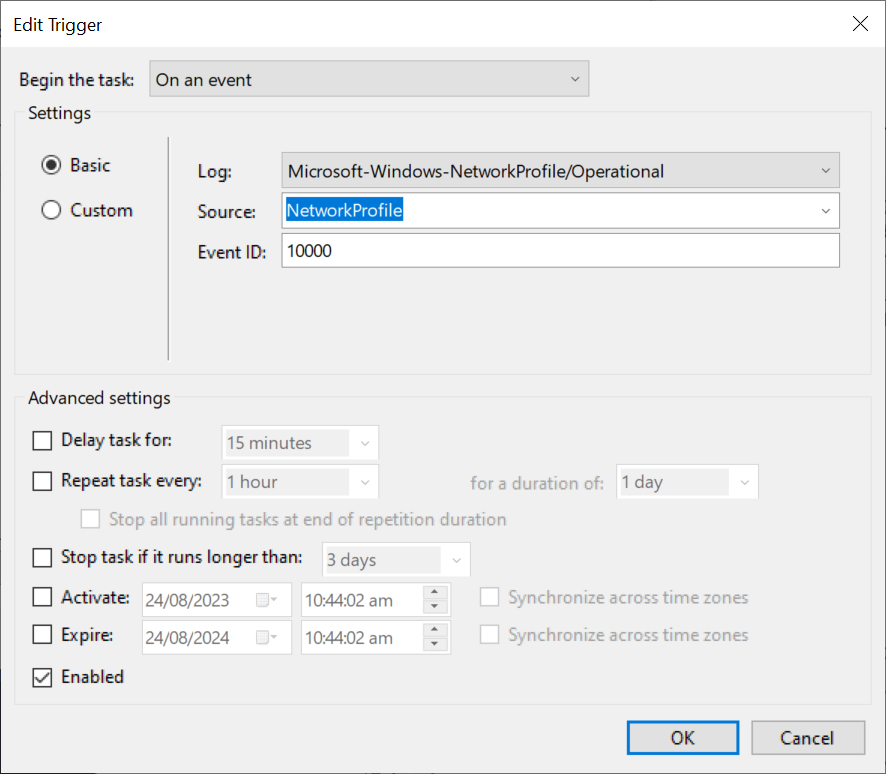
Step 3a: Create a powershell script to be run, stick it somewhere on your C drive, such as C:\scripts: Sample script:
# vpn-script.ps1 # Ensure that the script can run by setting the execution policy Set-ExecutionPolicy Bypass -Scope Process -Force # Change the interface metric for Cisco AnyConnect adapter Get-NetAdapter | Where-Object {$_.InterfaceDescription -Match "Cisco AnyConnect"} | Set-NetIPInterface -InterfaceMetric 4000 # Change the interface metric for vEthernet (WSL) adapter Get-NetIPInterface -InterfaceAlias "vEthernet (WSL)" | Set-NetIPInterface -InterfaceMetric 1Step 4: Create an action to do when triggered. Click New… and here we go
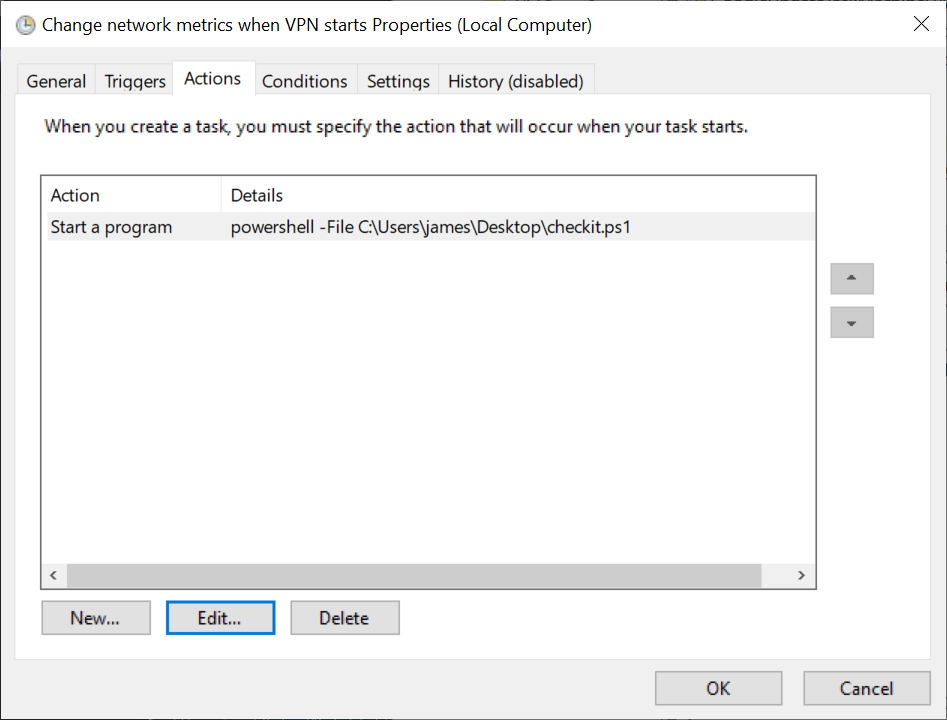
Step 5: Define our action as starting a progam, run powershell with the argument
-File C:\scripts\vpn-script.ps1(or whatever you want to call your script).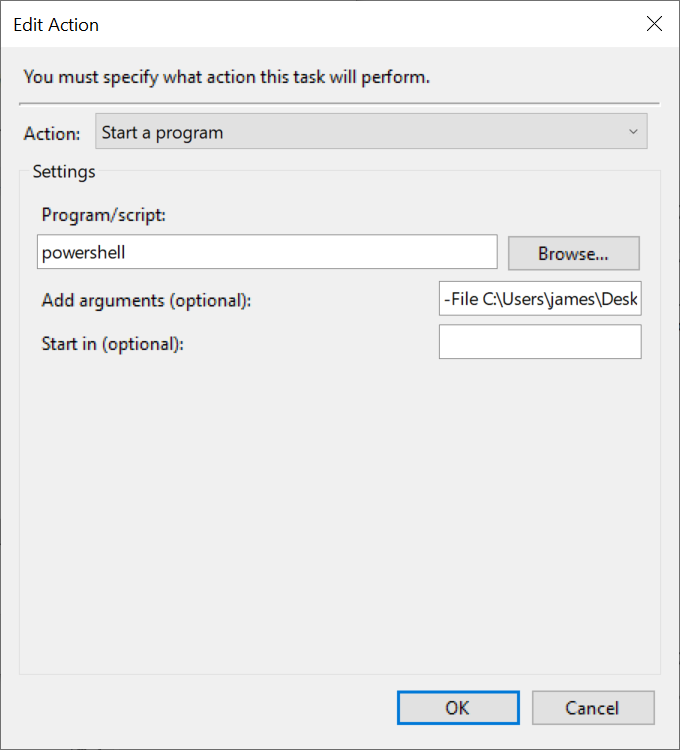
Now when we connect to AnyConnect, our WSL2 sessions should be able to route nicely (they will all go over the VPN, which in my case was desirable). We can test this by pinging google.com from our WSL2 session before and after joining the VPN. The latency (and dst IP) will likely change. If ping doesn’t work, something is wrong.
-
Juniper VRR on eve-ng
I have a fairly old Dell R720 server, running the neat multi-purpose Unraid OS. It’s primarily a file/media/whatever server. It’s hosting this webpage you’re reading. It’s also got a 30 core, 100 GiB RAM VM running eve-ng on it. For ages (as part of my procrastination to get a new cert, like finally pushing my JNCIP-SP into a JNCIE…) I have had eve-ng running with a mix of vMX and vSRX nodes. Due to the way vMX and vSRX work, they smash your CPU cores. This might be fine in a production environment, but for a lab designed to play with protocols - it’s overkill. This is especially bad when combined with running in a nested VM, sharing the server with more important things (like media serving…).
So - Juniper released a virtual route reflector, designed to only be a route reflector - running without DPDK CPU smashing. The result for me, was being able to run a 12 node lab, based on the
MPLS in the SDN Erabook - with a total CPU toll of around 20%. This is going down from constant 100% when using only a couple of vSRXes. Incredible, and just what I wanted. Quite similar to the ‘Olive’ SRX of yore.vRR is available from Juniper’s website the same way you can grab their other images (with an account and correct permissions).
Does the vRR do everything I want for my advanced MPLS lab work? Can it handle the EVPN jandal required for a JNCIE-SP in 2023? I will keep you posted. Overall, if you’re looking for a virtualised Juniper lab, vRR might be the way to go.
Shoutouts to Adam (@packetsource) for reminding me vRR exists!
-
Mikrotik Default FW Rules
I have been looking for a while for a good set of basic Mikrotik firewall rules. Default ones on the box are probably the best for a standard home user, so here they are:
/ip firewall filter add action=accept chain=input comment="defconf: accept established,related,untracked" connection-state=established,related,untracked add action=drop chain=input comment="defconf: drop invalid" connection-state=invalid add action=accept chain=input comment="defconf: accept ICMP" protocol=icmp add action=accept chain=input comment="defconf: accept to local loopback (for CAPsMAN)" dst-address=127.0.0.1 add action=drop chain=input comment="defconf: drop all not coming from LAN" in-interface-list=!LAN add action=accept chain=forward comment="defconf: accept in ipsec policy" ipsec-policy=in,ipsec add action=accept chain=forward comment="defconf: accept out ipsec policy" ipsec-policy=out,ipsec add action=fasttrack-connection chain=forward comment="defconf: fasttrack" connection-state=established,related add action=accept chain=forward comment="defconf: accept established,related, untracked" connection-state=established,related,untracked add action=drop chain=forward comment="defconf: drop invalid" connection-state=invalid add action=drop chain=forward comment="defconf: drop all from WAN not DSTNATed" connection-nat-state=!dstnat connection-state=new in-interface-list=WAN /ip firewall nat add action=masquerade chain=srcnat comment="defconf: masquerade" ipsec-policy=out,none out-interface-list=WAN /ipv6 firewall address-list add address=::/128 comment="defconf: unspecified address" list=bad_ipv6 add address=::1/128 comment="defconf: lo" list=bad_ipv6 add address=fec0::/10 comment="defconf: site-local" list=bad_ipv6 add address=::ffff:0.0.0.0/96 comment="defconf: ipv4-mapped" list=bad_ipv6 add address=::/96 comment="defconf: ipv4 compat" list=bad_ipv6 add address=100::/64 comment="defconf: discard only " list=bad_ipv6 add address=2001:db8::/32 comment="defconf: documentation" list=bad_ipv6 add address=2001:10::/28 comment="defconf: ORCHID" list=bad_ipv6 add address=3ffe::/16 comment="defconf: 6bone" list=bad_ipv6 /ipv6 firewall filter add action=accept chain=input comment="defconf: accept established,related,untracked" connection-state=established,related,untracked add action=drop chain=input comment="defconf: drop invalid" connection-state=invalid add action=accept chain=input comment="defconf: accept ICMPv6" protocol=icmpv6 add action=accept chain=input comment="defconf: accept UDP traceroute" port=33434-33534 protocol=udp add action=accept chain=input comment="defconf: accept DHCPv6-Client prefix delegation." dst-port=546 protocol=udp src-address=fe80::/10 add action=accept chain=input comment="defconf: accept IKE" dst-port=500,4500 protocol=udp add action=accept chain=input comment="defconf: accept ipsec AH" protocol=ipsec-ah add action=accept chain=input comment="defconf: accept ipsec ESP" protocol=ipsec-esp add action=accept chain=input comment="defconf: accept all that matches ipsec policy" ipsec-policy=in,ipsec add action=drop chain=input comment="defconf: drop everything else not coming from LAN" in-interface-list=!LAN add action=accept chain=forward comment="defconf: accept established,related,untracked" connection-state=established,related,untracked add action=drop chain=forward comment="defconf: drop invalid" connection-state=invalid add action=drop chain=forward comment="defconf: drop packets with bad src ipv6" src-address-list=bad_ipv6 add action=drop chain=forward comment="defconf: drop packets with bad dst ipv6" dst-address-list=bad_ipv6 add action=drop chain=forward comment="defconf: rfc4890 drop hop-limit=1" hop-limit=equal:1 protocol=icmpv6 add action=accept chain=forward comment="defconf: accept ICMPv6" protocol=icmpv6 add action=accept chain=forward comment="defconf: accept HIP" protocol=139 add action=accept chain=forward comment="defconf: accept IKE" dst-port=500,4500 protocol=udp add action=accept chain=forward comment="defconf: accept ipsec AH" protocol=ipsec-ah add action=accept chain=forward comment="defconf: accept ipsec ESP" protocol=ipsec-esp add action=accept chain=forward comment="defconf: accept all that matches ipsec policy" ipsec-policy=in,ipsec add action=drop chain=forward comment="defconf: drop everything else not coming from LAN" in-interface-list=!LANSometimes I struggle to find these. This set is from RouterOS 7.1.
-
Jekyll Post Generator
Today I remembered this blog, and what a pain it can be to write. Then I found this nice Gist, which houses a couple of Bash scripts to auto-generate the skeletal files required to make a Jekyll post - and life got a little better. I plan to improve on them a bit, they’re a bit jank - but it’s a great place to start.
Check it out here if that’s your thing: https://gist.github.com/aamnah/f89fca7906f66f6f6a12.
I have updated it a little, adding a couple of options that automatically create a nicer page in Jekyll (permalink), and added time to the date, so creating multiple posts in a day shows up in order.
# Create a new jekyll post with the current date and the given title # and print the path to the post file. # # author: andreasl post_title="$*" [ -z "$post_title" ] && printf 'Error: Script needs a post title.\n' && exit 1 #repo_dir="$(git rev-parse --show-toplevel)" repo_dir="/home/james/blog" post_date="$(date '+%Y-%m-%d')" post_datetime="$(date '+%Y-%m-%dT%H:%M:%S%:z')" title_slug="$(printf -- "$post_title" | sed -E 's/[^a-zA-Z0-9]+/-/g' | tr "[:upper:]" "[:lower:]")" post_path="${repo_dir}/_posts/${post_date}-${title_slug}.md" [ -e "$post_path" ] && printf 'Error: Post exists already.\n' && exit 2 IFS= read -r -d '' front_matter << EOF --- title: "${*}" date: ${post_datetime} tags: [] layout: post permalink: /${title_slug}/ --- EOF printf -- "${front_matter}" > "${post_path}" printf -- '%s\n' "${post_path}" -
Whoops
Well, about 11 months ago I wrote the last post on this blog. What a total pain. I moved continents with my family, I’ve had 3 jobs since that last post. It’s been weird.
Things are settling back down now, I’m working for a US based startup doing internet things, which is neat. I’m going to try and knock out some useful posts at some point.
Still using Jekyll, but honestly I blame it for making writing more difficult than it previously was under Wordpress. We’ll see. Also, Wordpress is garbage now!
See you soon (or in nearly a year, who knows).